To claim or not to claim: how I helped improve Full Fact’s automated factchecking
When I started my MSc in Data Analytics at Warwick University, working towards factchecking wasn’t something I was considering. In fact, I barely knew that such organisations exist. So when my supervisor, Arkaitz Zubiaga, emailed me saying that I’d be suited to doing my dissertation with a factchecking charity that was looking for a student, I was intrigued.
After visiting the Full Fact website, and watching talks by members of the Full Fact team, that intrigue turned into excitement.
What resulted was a nine month collaboration from January to September 2018. The output was a paper that improves state of the art algorithmic claim detection by five percent and an improvement to the Full Fact tool Live.
As well as this, I had the pleasure of spending eight weeks over the summer in the Full Fact office, giving me an opportunity to meet members of the team and to see how the factchecking works beyond the tech – the entire factchecking pipeline (the pipeline includes going to the pub).
Join 74,000 newsletter subscribers who trust us to check the facts
Sign up to get weekly updates on politics, immigration, health and more.
Subscribe to weekly email newsletters from Full Fact for updates on politics, immigration, health and more. Our fact checks are free to read but not to produce, so you will also get occasional emails about fundraising and other ways you can help. You can unsubscribe at any time. For more information about how we use your data see our Privacy Policy.
Working at Full Fact
Full Fact’s staff are super welcoming, there is a dog called Pico, and one of London’s best parks, St. James’s, sits right next door. As a student, eliminating the ability to procrastinate is a blessing, and the environment at Full Fact was great for that. Had I spent my summer doing my dissertation at home, I doubt I would have achieved so much.
If you are a prospective student looking for dissertation topics and Full Fact are looking for students, I strongly recommend showing an interest! As well as masters students, they’ve hosted students on the Imperial Charity Insights scheme, Google News Fellows and sometimes run paid internships.
My work at Full Fact
One of the most mechanical parts of a factchecker’s job is to identify when people actually make claims that need to be factchecked. Typically a factchecker will monitor a debate or read live transcripts, noting down whenever a checkable claim is made, before deciding whether or not to factcheck it.
But what if finding checkable claims could be automated? Enter the tech team.
Claim detection
The first major part of my collaboration with Full Fact was spent building a claim detection model that could read a sentence, and tell you whether or not it contains a claim. This is done by combining Natural Language Processing (NLP), the computational study of human language, and Machine Learning (ML).
That may make it sound complicated but it’s quite simple: you take some data with sentences labelled as “claim” or “not a claim”, decide on an algorithm, and tell the algorithm to learn the characteristics of the sentences labelled “claim” and those labelled “not a claim”. Then you see how well it works on new sentences that it’s never seen before.
Believe it or not, one of the most challenging and important parts of this is not deciding on an algorithm, or making it learn the characteristics, but actually defining and generating the data from which it can learn.
Since Full Fact are a charity, they are lucky enough to be embraced by an amazing community of volunteers, who are passionate about stopping the spread of misinformation. 80 volunteers were were given many thousands of sentences, and labelled (or “annotated”) them using a cool tool called Prodigy.
The annotation interface looked like this:
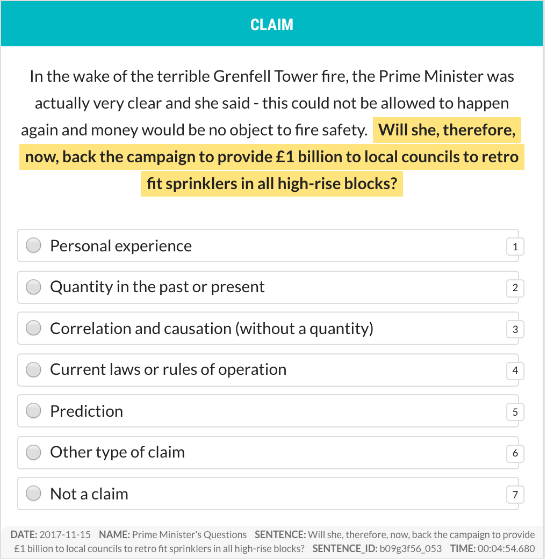
After accounting for annotator disagreements, and reducing the 7 options into “claim” and “not a claim”, we had some 5,000 sentences on which to build our models.
After several months of working on this with the help of Lev from Full Fact, and Arkaitz, my supervisor, we discovered the best model for this claim detection task!
Our final system was accurate about 83% of the time, which was a pretty significant improvement on what was out there already.
It’s a great feeling building a successful model, but it’s even better seeing it in action.
I was lucky enough to see the claim detection model being used for live factchecking. The team at Full Fact integrated it into their automated factchecking tools.
So whilst Prime Minister’s Questions (PMQs) is on TV, the factcheckers get a live stream of the transcript on their computers, and the algorithm I helped create highlights the sentences in bold when it identifies a claim that could be checked.

We wrote all of this up into a journal paper that is going to be presented and published at the EMNLP conference in November. You can read it for yourself here.
Thank you to the team at Full Fact, and everyone at Warwick, for making this project a reality.