Customising annotation tools for factchecking at scale
Full Fact is the UK's independent, non-partisan, factchecking charity. We are funded by individuals, trusts, foundations and many others. Our work on automation is funded by Google, Open Society Foundations and Omidyar Network. We work to anchor public debate to reality by providing independent factchecking. We've been doing this since 2010. Our work on automation started in 2013 and has been growing since.
With the continuous increase in news and commentary being published, there's a worldwide need to scale up the work of factcheckers. That's why we're working with partners around the world, and sharing the tools we create, so that we can have maximum impact.
To do this, we're working on artificial intelligence that can help us identify when a speaker or writer is making a specific, verifiable claim, and eventually even help us check those claims.
As a starting point, if the software can identify the claims, human factcheckers can focus on factchecking them, without reading all the irrelevant text. This means the software does shallow processing of lots of text, while humans work on questions that require lots of context and reasoning—the important ones!
Our work on automation is split into two tracks: building our two products (Live and Trends) and doing research. Hopefully the research then informs how we can improve our products further down the line.
One of the first research projects we took on was to automatically detect and classify claims into certain categories. Work has been done before on identifying claims, but here we’re trying to automatically detect claims and categorise them by the type of claim they are. This is the kind of reasoning our factcheckers go through when they check something manually.
To build a model that can automatically detect the type, we need a large number of examples. In our case we have 5,000 sentences from political shows which need to be classified. Each sentence needs five people to classify it, so by the end we should have 25,000 classifications, or annotations, that the model can learn from.
We put out a call in our newsletter for volunteers willing to help us trawl through these sentences and classify them into different categories.
We got a great response. 200 people signed up, and 90 people said they could help us that month.
But how do you get 90 people categorising sentences for you at the same time?
Join 74,000 newsletter subscribers who trust us to check the facts
Sign up to get weekly updates on politics, immigration, health and more.
Subscribe to weekly email newsletters from Full Fact for updates on politics, immigration, health and more. Our fact checks are free to read but not to produce, so you will also get occasional emails about fundraising and other ways you can help. You can unsubscribe at any time. For more information about how we use your data see our Privacy Policy.
Enter Prodigy
Prodigy is an annotation tool powered by active learning. It solves the problem of collecting annotations and putting them directly into a system that learns over time. We were lucky enough to be put in touch with Ines and Matt at Prodigy through Lev, our Natural Language Procesessing (NLP) engineer who has collaborated with them in the Python NLP world. (Check out spaCy and gensim.)
When it first started out Prodigy was meant for one person to collect annotations. It was on their roadmap to add multi-user access, but we needed it sooner.
Ines and Matt gave us their blessing to use and customise Prodigy for our specific use case. We aren't doing any active learning yet but we are collecting annotations from many different people. So on top of what Prodigy can do already we had the following requirements:
- We wanted Prodigy to be accessible to Full Fact's many volunteers and have a record of who annotated which sentences.
- We didn’t want them to have to annotate sentences they have annotated before.
- We didn’t want sentences to be over-annotated. Once a sentence has been annotated enough that we can decide whether it is a claim or not, we want to stop sending it to volunteers.
To deliver these requirements we implemented the following:
- A prodigy process manager
- A proxy server—this is the thing that points people in the right direction
- A task server—this is the thing that serves the 'tasks' (the sentences for volunteers to classify)
- A custom Prodigy "recipe" to display our annotation tasks and communicate with the task server.
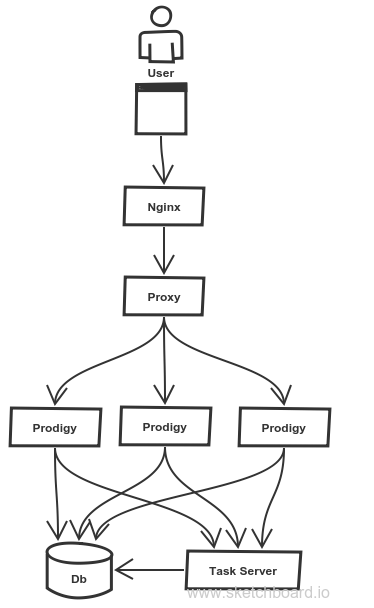
The Prodigy Process Manager
Because Prodigy does not currently support native multi-user access (i.e. lots of people at once), we needed to give each user their own copy of Prodigy.
We implemented a simple Python process that has user details as part of its configuration. It starts up a copy of Prodigy for each configured user and makes sure it stays up.
Each instance was given the same label, CLAIM, and a user-specific dataset name. They also get their own statically determined port to allow the proxy server, described below, to know where to route volunteers.
This worked seamlessly. The main downside of this approach is that it needs a lot of memory. At the moment, we have 90 volunteers live with the corresponding 90 Prodigy instances which altogether adds up to 5.5 GB of memory.
The Proxy Server
We decided we wanted to send each volunteer a username and password which would allow them access to their own copy of Prodigy. So we needed something that would authenticate these access details and route requests to the correct copy of Prodigy. A simple Python process written using Flask achieved this aim.
The Task Server
To achieve the flexibility in serving tasks live to multiple volunteers we implemented a task web service. The task server exposes a pair of endpoints, one to allow the prodigy instances to get tasks, and the other allowing us to submit tasks to be served.
The task server was smart enough to handle our requirements around serving specific tasks. We used a combination of Python logic and Postgres views (an open source database) to extract enough information from the Prodigy database to implement our requirements.
Our recipe for customising Prodigy
Here's a demo of Prodigy out of the box. Here’s what a volunteer saw when they signed in with our customised version:
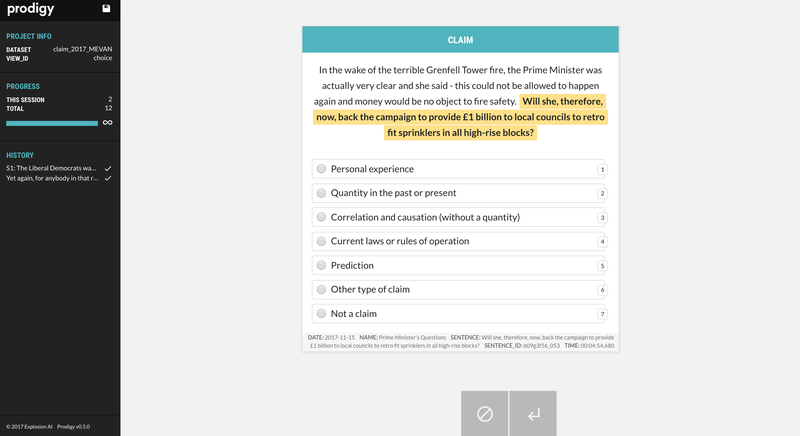
We got rid of some of the buttons at the bottom better suited to active learning. We're planning on bringing those back quite soon when we move onto the next stage of our work.
This task came with a lot of guidance on how to classify the sentences. In the space of a few weeks we managed to collect 25,000+ annotations. We’ll be publishing the results of our findings soon, but what's certain is we wouldn't have got as far as we have without Prodigy, our amazing volunteers who donated hours and hours, and to all the people who donate to keep Full Fact running. Thank you!