Full Fact AI
Every day fact checkers around the world find, check and challenge false claims identified by AI enabled software produced by Full Fact.
We have built scalable, robust software designed for fact checkers, and other organisations focused on good information, to save time, money and effort in identifying the most important bad information to address.
If you want to use or test our software, please get in touch.
Our goals
Sharing accurate information helps to build a society where better decisions are made, trust is earned, and democracy thrives.
Fact checking claims made by politicians, public figures and viral online content can give us the full picture backed by the evidence.
Since 2016, we've been using machine learning to improve and scale fact checking, working with international experts to identify how artificial intelligence can transform this work, to develop new tools and to deploy and evaluate them.
These tools are now available for other organisations to use via a paid licence. Our goal is to create a global collaborative effort to help media outlets, civil society, platforms and public policy makers better understand the landscape, and to bring the benefits of those tools to everyone.
Our impact
When a popular two-hour long podcast recently shared serious vaccine misinformation, our tool was able to identify the relevant section, saving our fact checkers a lot of time. When a number of MPs were repeating the same misleading claim about migrant numbers, our tool found these repeats so we could ask them to to correct the record. And when a wellness company shared unreliable research about the "female health gap", our tools brought it to the attention of our fact checkers and as they investigated it, also helped them to discover how widely it had been repeated.
Our tools are now used by over 40 fact checking organisations working in three languages across 30 countries on a daily basis, to help experts use their knowledge of national and regional affairs and issues of importance more effectively. Through 2024, the tools were used to support fact checkers monitoring 12 national elections. On a typical weekday, our tools process about a third of a million sentences in total.
When we introduced our tools to 25 Arab-speaking fact checking organisations, they reported that media monitoring had become faster and simpler and many started live-monitoring of events for the first time. Over 200 fact check articles have been published about claims found there using our tools.
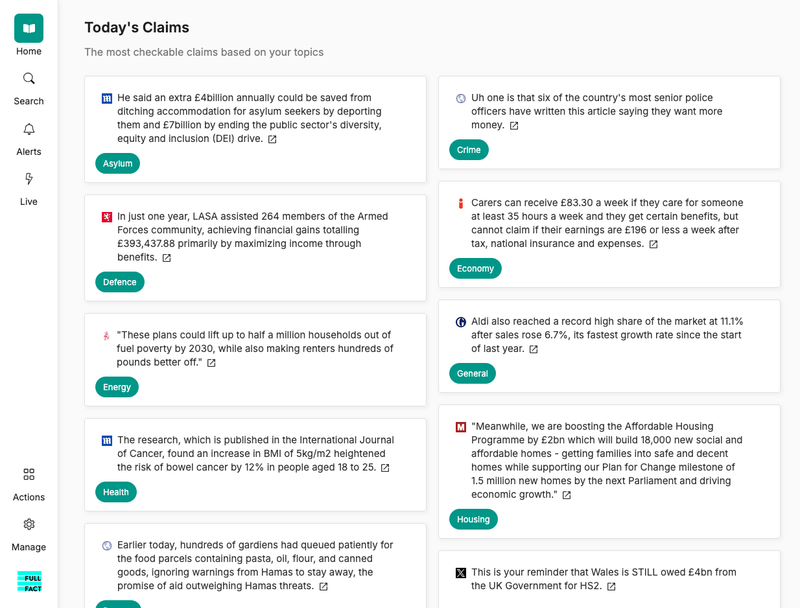
What we are building
We have made a set of tools designed to alleviate the pain points we experience in the fact checking process. As fact checkers with ten years’ experience, we understand the operational advantages these tools can bring, making us uniquely placed to build them.
We want to use technology to help:
- Know the most important thing to be fact checking each day
- Know when someone repeats something they already know to be false
- Work as close to real-time as possible
Across a suite of products, our technology helps with the following tasks:
Collecting and monitoring the data
Data we collect can be taken from online news sites, speech on live TV, podcasts and social media pages. Our users are able to choose for themselves the sources they are interested via a simple UI.
Once we have all the raw data available as text we split everything down to individual sentences, which are the atomic units of our work. The sentences are then passed through a number of steps to enrich them and make them more useful.
Identifying and labelling claims
We define a claim as the checkable part of any sentence.
There are many different types of claims, ranging from claims about quantities (“GDP has risen by x%”); claims about cause and effect (“this policy leads to y”); predictive claims about the future (“the economy will grow by z”); and more.
We have developed a claim-type classifier to guide users towards claims that might be worth investigating. We built this with the BERT model and fine-tuned it using our own annotated data. BERT is a "large language model" released by Google Research that has been pre-trained with hundreds of millions of sentences in over 100 languages. This makes it a broad statistical model of language as it is actually used and helps us build tools designed to work in an equally wide range of languages.
Labelling claims in this way filters the volume of data we process from hundreds of thousands to tens of thousands. For example, fact checkers are usually not interested in people's predictions because they cannot be verified. We use our version of BERT to identify and remove these types of claims from further consideration. It is a vital first step in ensuring that our users have a chance to make sense of all the information. We then filter these claims further by topic (like health and the economy) to ensure a time-poor user can instantly see the important claims on a topic without being overwhelmed.
Matching claims
Once we have labelled claims, sentences are checked to see if they are a match to something we have previously fact checked. Some claims are easier to model than others due to specificity and ambiguity in the language used to describe them.
Previously, we built a hybrid machine learning model to predict match/no-match for sentences including components like sentence vectorization and entity analysis (e.g. check if both sentences refer to the same people, organisations, numbers etc.). In combination, these stages consistently find repeats of a claim even if different words are used to describe it.
More recently, we've enhanced this approach by introducing a generative AI model. We found that this needs far fewer examples to learn from, making it much easier for us to adapt it to work in other languages and support users around the world.
Once the claim has been identified
The fact checking process is often undertaken offline by our team of expert fact-checking journalists. We then publish the results on our website. We also describe each fact check with some very specific markup, called ClaimReview, which is part of the wider schema.org project. It describes content on a range of topics in domain specific terms. This is important for us as describing our content so specifically helps ensure that our fact checks can travel further than our own platforms. Fact checks can form a vital part of the web. Over 130,000 fact checks exist in the Google Fact Check Explorer and these were seen over 4 billion times in 2019 in Google Search alone.
Limitations
We are careful not to overstate our results. There are a lot of people who say that artificial intelligence is a panacea but we have been on the front line of fact checking since 2010 and we know first hand how difficult it is. Human experts aren't going anywhere anytime soon — and nor would we want them to be.
Our AI team is made up of:
- Andy Dudfield, Head of Full Fact AI
- Kate Wilkinson, Senior Product Manager, Full Fact AI
- David Corney, Senior Data Scientist
- James McMinn, Senior Software Engineer
- Ed Dearden, Data Scientist
- Adam Garscadden, Frontend developer
- Nina Menezes, Web developer
We need support and funding to develop this work further. Please get in touch if you can help.