The Quest for the Questions in BBC Question Time
This is the second post of two from Michal who joined Full Fact for two weeks in November. You can read the first one here. He analysed subtitles from BBC Question Time. This article is cross-posted on his blog.
Join 74,000 newsletter subscribers who trust us to check the facts
Sign up to get weekly updates on politics, immigration, health and more.
Subscribe to weekly email newsletters from Full Fact for updates on politics, immigration, health and more. Our fact checks are free to read but not to produce, so you will also get occasional emails about fundraising and other ways you can help. You can unsubscribe at any time. For more information about how we use your data see our Privacy Policy.
Introduction and the problem
Let me demystify the tongue-twisting title a bit.
As I described earlier, the show BBC Question Time is organised around a few “big questions” asked by the audience.
I would like to build the classifier that will take all questions asked during a particular show and classify each one as “big” or not.
Why is this important? If one could do it automatically this would separate the show into “independent” parts, possible to analyse in parallel by different Fact Checkers. Another application would be to use the algorithm to automate the generation of the dashboard described in the previous post, which requires prior separation into themes.
The task should be fairly easy on the basis of the preceding sentences. Usually, the host of the programme provides some introduction, characteristic for the new theme. Have a look a these examples from the 2017.12.07 episode:
-
Would Brexit make an ideal theme for a modern Christmas pantomime?
-
Might a no-deal Brexit actually be the best result for Britain?
-
Is Donald Trump right to recognise Jerusalem as the capital of Israel?
-
Should we allow anybody who has fought with Isis back into the country?
So in plain text, let us look at one example of “big question” and preceding context:
Right, and now I’m going to leave that point. This is a serious issue and it’s got to be determined over the next whatever it is. Jonathan Jennings, let’s have your question and go to the heart of the matter. Might a no-deal Brexit actually be the best result for Britain?
and one “small” question, thrown in during the debate:
Liz, you said… In your view, we should stay both in the single market and the customs union. So anything other than that, you think, would be a disaster?
So the task here is to build a classifier that predicts if the question is “big” one or not, on the basis of a few preceding sentences (I will call them context sequences). Focusing on preceding sentences is convenient, because it allows the algorithm to run in an on-line mode, classifying questions live as they appear.
The training data
To train the classifier one needs the training data. This means extracting the “big questions” from the past shows. This is a bit daunting since one has, in principle, to skim through each show. This is the only foolproof way to extract the questions…
Luckily, there is a sweet shortcut, which allowed me to label relatively large dataset fairly quickly. BBC Question Time is active on Twitter and essentially “broadcasts” the questions live during the show. You can retrieve them searching for tweets from the account BBCQuestionTime containing the word “question” on the date of the show. Have a look at results for 2017.12.07 episode.
Not bad, there are a few extra tweets, but all the “big questions” are there. Accessible much faster than by browsing the subtitles. Unfortunately, they are all in bitmap form preventing further automation via Twitter API.
Anyway, using the above shortcut I was able to label 42 shows containing 213 “big questions” and 3428 “small” ones.
Models
I built a few simple models on bag of words representation of a few (from one to three) sentences preceding each question. On that basis, models tried to separate the “big” ones from ordinary questions. I started with a few standard ML no-brainers — logistic regression with L2 regularisation (LR), random forest (RF), and extra trees (ET).
As far as text preprocessing is concerned I used Porter stemmer. In addition, all capitalised n-grams were replaced by dedicated placeholders (e.g, John Smith was replaced by capitalised_2gram). This is a very simple form of recognising named entities. The raw word counts were used as features, for the LR the min-max normalisation was additionally applied.
The model comparison was based on the 5-fold cross validation scores. I used stratified version. In addition, I also wanted all questions from each show to end up in the same fold. This is the usual procedure, if you have multiple-source data. The samples coming from one source (in our case from one show) might be somehow similar to each other. Therefore, if the classifier sees some samples from a show, the rest might be slightly easier. In our case, I would not expect it to be a game changer. However, this problem has bitten me a few times, so I prefer to stay on the safe side. If you are more interested in the multiple-source cross-validation, I recommend this paper.
In this case, I decided care equally well for the precision and recall. Therefore, I chose the cutoff probability for classifiers in a way that precision is equal to recall. Changing the cutoff in any direction would result in either decreasing the precision at the cost of recall or in the opposite trade-off.
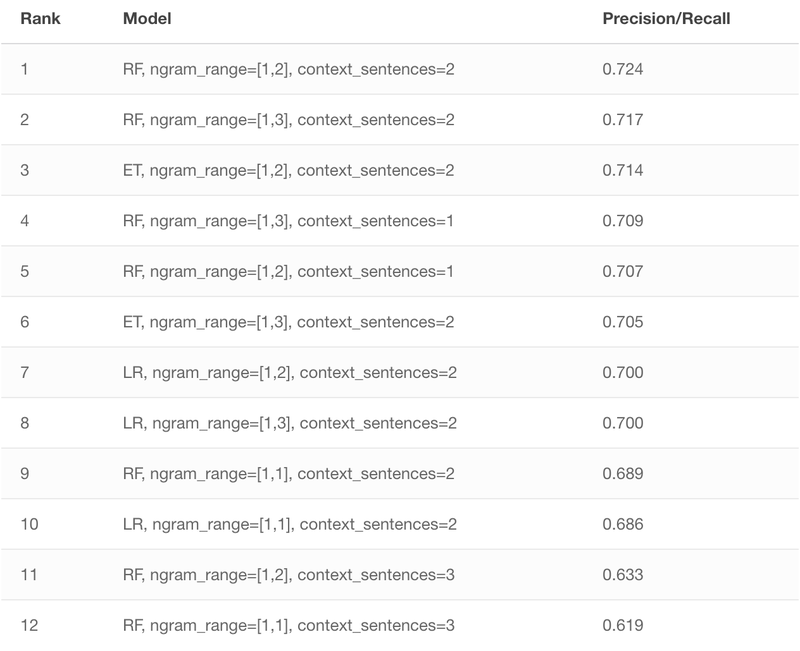
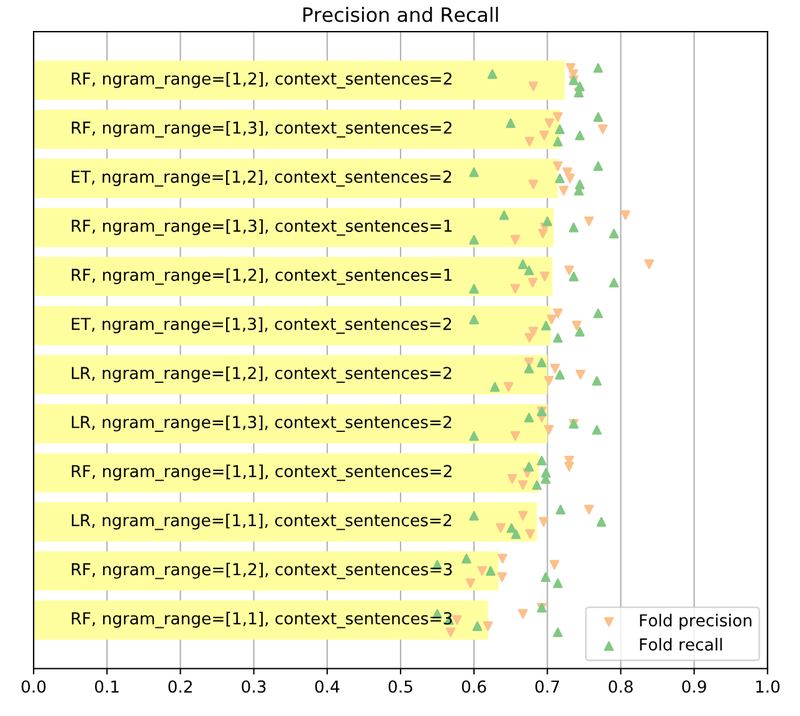
The above data can also be presented in the graphical form, see the barchart below. I also included the scatter plot displaying the results from individual folds.
Quick look into important features
Luckily, the examined models can provide some insights into their “inner workings”. Random forest computes feature importance. Logistic regression also has coefficients associated with each feature, which can be interpreted as feature weights (yes, yes there are a lot of caveats to that, but I will ignore them for now). For easier interpretation, I will focus on unigram case, both for RF and LR.
Let us have a look at top ten most important words (after Porter stemming!) according to the RF model:
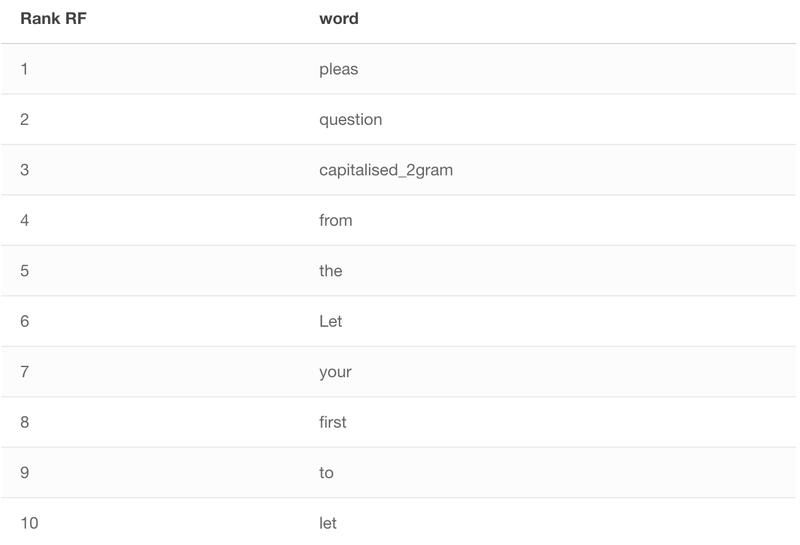
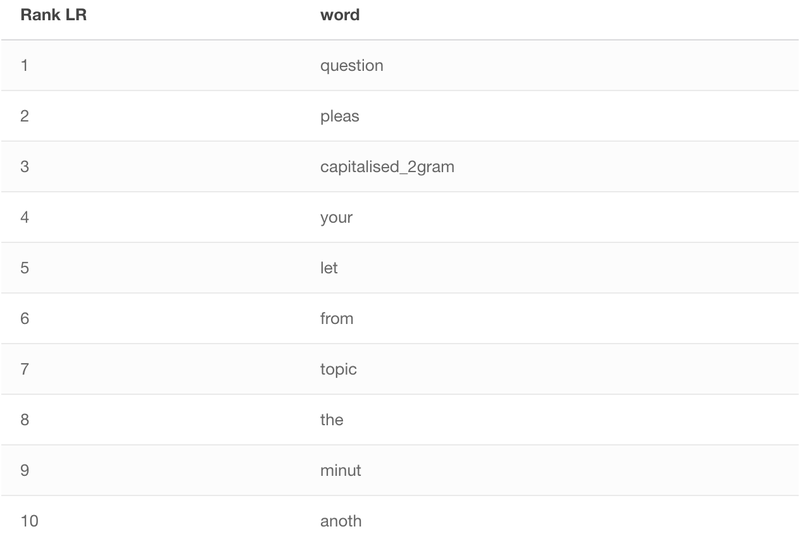
Interestingly, there is quite a high overlap. Both models have picked up elements of the typical phrases used by David Dimbleby while introducing new question (We have to move on, let us have another question from John Smith. John Smith, please., etc.)
Conclusions
In this blog post, I looked at the machine-learning way for detecting the big questions in BBC Question Time subtitles. I built a few ML models to accomplish the task on the basis of bag-of-words built from a few sentences preceding the analysed question.
As far as the features are concerned, it turned out that two preceding sentences of the context was the sweet spot. Either taking one or three sentences before a question degraded the performance. Unigrams and bigrams provided the best results. Including trigrams, or restricting to unigrams only also reduced the performance. When it comes to models, tree-based techniques (random forest, extra trees) turned out superior to logistic regression.
Finally, the best models reached around 72% precision/recall score. This means that they detect 72% of all true big questions and at the same time have 72% proportion of real big questions to false ones in a positively classified group. Not bad, but for serious production application one would like to have both numbers above 90%. Luckily, the approaches discussed above leave a lot of room for further experiments…
Acknowledgements
I thank the whole Full Fact Crew, especially the Digital Team and Lev Konstantinovskiy for the creative atmosphere and many hints during the project. I heartily recommend working with Full Fact, either as a volunteer or within any other opportunity at hand.